bolt数据库是golang开发的简单的kv数据库。代码十分精简,总共3000+行,学习数据库一个比较好的起点。
bolt使用的数据结构按照数据保存的位置划分两类:内存和磁盘。
内存中的数据结构核心是B+树,它根据key组织在一起。B+树中的每个结点,对应数据结构node,其中的内部信息通过数据结构inode来描述。内存中其他主要数据结构还包括meta和freelist。
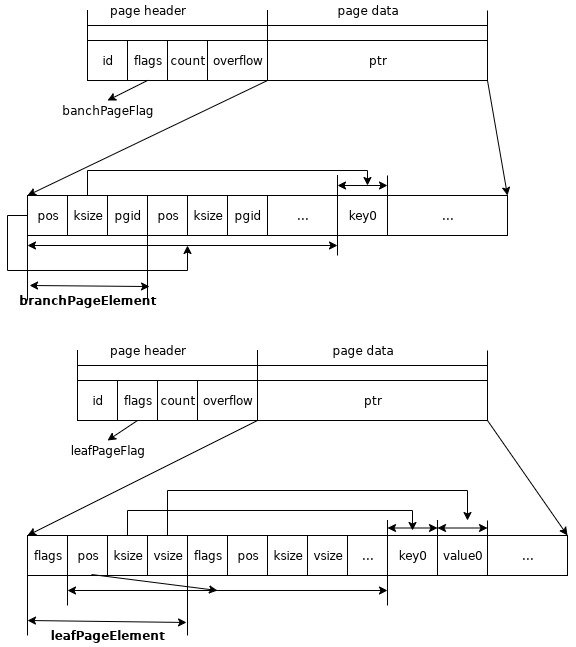
描述磁盘中的数据结构是page,它的数据来自于node、meta或者freelist。对应者一块内存,大小为os的page size的倍数。
type node struct {
bucket *Bucket // 这个结点所在的的bucket
isLeaf bool // 是否是叶子结点
unbalanced bool // 是否平衡,删除的时候做标记
spilled bool // 是否已经分裂
key []byte // 对应着第一个inode中的key
pgid pgid // 所在页的id
parent *node // 父结点
children nodes // 子结点
inodes inodes // 结点中key或者key&value,如果是分支结点只有key,叶子结点还有value
}
通过branchPageElement或者leafPageElement来获取数据。
type inode struct {
flags uint32 // 标记,用来区分支结点和叶子结点
pgid pgid // 所在页的id
key []byte
value []byte
}
代表一个页或者连续的几个页。
type page struct {
id pgid // 64位的id
flags uint16 // 页的标记,表示存储的数据类型,包括分支、叶子,元数据和描述空闲页的数据
count uint16 // 包含数据的元素个数
overflow uint32 // 后面还有的页数
ptr uintptr // 只是一个标记字段,标记数据的起始位置
}
B+树中分支结点保存的数据元信息。
type branchPageElement struct {
pos uint32 // 本元素的地址到key的起始地址的距离
ksize uint32 // key的大小
pgid pgid // 页id
}
B+树中叶子结点保存的数据元信息。
type leafPageElement struct {
flags uint32 // 标识这里主要用于区分是bucket还是一个普通的value
pos uint32 // 本元素的地址到key的起始地址的距离
ksize uint32 // key的大小
vsize uint32 // value的大小
}
以上三者之间的关系如下图
type freelist struct {
ids []pgid // 空闲页的id数组
pending map[txid][]pgid // 每个写事务spill的时候释放的页,这些页在commit的时候会被释放掉
cache map[pgid]bool // 帮助快速查询空闲页和等待释放页的一个cache,仅仅是用来检查是否重复释放的bug
}
bolt数据库采用了写时复制的策略,因此数据更新的时候,会新建一个页保存更新以后的数据,那么原来的页就可以重复利用了。这些页通过freelist管理。因为page数据结构count地址的限制,它能保存的最大值是0xFFFF,所以空闲页数量大于0xFFFF的时候,需要添加一个长度头来表示有多少空闲页。
pending的page需要确保没有被其他事务引用时才能释放被重新使用。所以,bolt的处理方式是在开始写事务的时候找到最小的事务id,然后把小于该事务id引用的page给释放掉。
它和page的存储关系如下:

类似关系型数据库中的表。它可以包含子bucket。bolt中有一个根bucket,所有的数据和bucket都保存在这个根bucket中。每个bucket对应一棵B+树。
bucket的数据很少时会做一个优化。这个条件是bucket对应的根数据页是叶子结点,同时它的数量(pageHeaderSize+leafPageElementSize+key size+value size)小于page size的1/4。
通过bucket可以设置在B+树中与它相对应结点的分裂阀值。如果写操作几乎是追加操作可以提高这个值,否则还是不要太大了。这是因为,如果更新很频繁化,阀值很大情况下就会有更多脏的page。这会增加写的压力。
type Bucket struct {
*bucket // 保存在文件中的数据信息
tx *Tx // 事务
buckets map[string]*Bucket // 子bucket cache
page *page // 当bucket可以inline时,数据页
rootNode *node // 对应根数据页的内存数据结点
nodes map[pgid]*node // 结点cache,有写操作的bucket才会初始化
// 结点分裂的阀值。默认是page size的50%。如果写操作几乎是追加的情况下可以增加这个值。
FillPercent float64
}
// Bucket在文件中的表示,它是bucket key的值
// 如果bucket很小,可以把bucket中其他的kv数据保存在这些数据保的后面,这个时候root值是0
type bucket struct {
root pgid // 根数据页的id
sequence uint64 // 单调递增序号,被NextSequence调用
}
它和page的关系如下:

有序遍历的游标,读写的时候用。只在一个事务中有效。遍历的时候如果修改了数据,它返回的数据是不确定的。
通过栈的方式记录遍历的每层结点,栈顶是叶子结点。每次访问数据的时候需要遍历到叶子结点。因为叶子之间没有指针,所以需要回溯分支结点。
type Cursor struct {
bucket *Bucket // 当前的bucket
stack []elemRef // 遍历的堆栈
}
// 遍历的结点信息
type elemRef struct {
page *page
node *node
index int // 分支结点或者叶子结点中inodes的下标
}
type Tx struct {
writable bool // 是否是包含写操作事务
managed bool // 一个标志,防止事务被提交或者回滚
db *DB // 数据库实例
meta *meta // 元数据
root Bucket // 根bucket
pages map[pgid]*page // 事务中新分配数据页,有写操作的事务才会初始化
stats TxStats // 统计状态
commitHandlers []func() // 提交时的handler
// 写操作的一些选项
// 比如:当文件大小比内存大的多的时候,设置syscall.O_DIRECT可以避免page cache的失效
WriteFlag int
}
数据库的元信息。
type meta struct {
magic uint32 // 魔数0xED0CDAED
version uint32 // 版本
pageSize uint32 // 页大小
flags uint32 // 暂时无用
root bucket // 根bucket,它是所有数据的起始bucket
freelist pgid // 空闲页描述信息所在的数据页
pgid pgid // 最大数据页id
txid txid // 事务id
checksum uint64 // 元数据的校验和
}
它和page的关系如下:

单文件存储。读写单位是os的page size。通过多棵B+树组织在一起,不过这个B+树的叶子结点没有指向兄弟叶子结点的指针。每棵B+树和Bucket一一对应。
通过内存映射读取数据。
同时,需要管理空闲的磁盘空间,重复利用。
当发生添加数据或者修改时,被修改的数据所在的page都会被写到新的page。这样的好处就是事务隔离实现比较简单。
元数据描述了数据文件的结构,主要是B+树的结构。它保存在第0和1个page。
两个meta数据,这是为了解决只有一个meta并且如果写meta数据时进程挂情况下,整个数据库就没法读取了。参考这个issue。
每个写事务都会关联一个meta,交替使用两个meta。事务0使用meta0,事务1使用meat1等等。按照txid大小、数据是否有效两个维度的优先级选择meta。commit的时候会把meta的txid写到page中去。page的选择也是交替的,根据txid%2选择page id。
由于,写事务是互斥的,如果一个meta数据失效了,另外一个是正常的可以使用。之前关联这个失效meta的事务生成的数据都会丢失。当然,如果两个写事务写meta的时候都写失败了,那数据就真坏了。
以下几个条件满足的原子性:
它的持久性和并发模型决定隔离级别属于重复可读。
每次写事务提交的时候,都会把数据刷到磁盘。
写数据的顺序是freelist、数据、meta数据。只有meta数据写成功以后才算数据写成功。否则,整个事务的操作就会被回滚。
bolt数据库支持多个读事务和一个写事务同时进行。由于写事务分配数据的时候,因为超过文件大小,就需要重新做内存映射。为了避免读事务会读取这些数据,因此读事务开始的时候会获得内存映射的读锁。所以,因为这个锁有可能把写事务给阻塞。