功能
store模块是rocketmq的核心模块。主要功能有:
- 消息存储
- 消息索引
- 消费队列
- 主从同步
- 延迟消息
- 清理过期的消息和消费队列
消息存储
负责消息存储,包括写消息,刷盘。
消息文件
消息保存在默认值为${user.home}\store\commitlog文件夹下,可以通过配置项storePathCommitLog修改。所有的消息都写入一个逻辑文件,每个逻辑文件包含大小相等的物理文件。
写消息
写消息在不同的场景下面会有不同的逻辑。
同步刷盘
每条消息要写到磁盘以后才算完成。
在同步刷盘的场景下,会有一个定期检查消息是否已经写入磁盘的线程:GroupCommitService,除了检查还会进行刷盘的操作 。写消息的时候会生成一个GroupCommitRequest提交到GroupCommitService,并等待被唤醒或者超时。当GroupCommitService发现已经刷盘的最后一个消息的索引大于等于本消息的索引时就会唤醒GroupCommitRequest。
备注:以上的场景还依赖于消息的属性WAIT,只有该属性为空或者为true才会执行同步刷盘逻辑,默认是空的。
异步刷盘
在异步刷盘的场景下,会有一个把数据刷到磁盘的辅助线程:FlushRealTimeService。写消息仅仅唤醒该线程就结束了写盘操作。
主从同步
每条消息要等一个从broker同步完才算完成。
在主从同步的场景下,会有一个定期检查消息是否已经被从broker同步的辅助线程:GroupTransferService。写消息的时候会生成一个GroupCommitRequest提交给GroupTransferService,并等待被唤醒或者超时。当GroupTransferService发现从broker已经同步的最后一个消息的索引大于本次消息的索引时就会唤醒GroupCommitRequest。
写buffer
使用了写buffer以后,写消息的全部逻辑就是把消息写入buffer。同时,系统会有一个线程CommitRealTimeService定期把消息写入文件。
核心代码
org.apache.rocketmq.store.CommitLog
消费队列
每个topic对应多个消费队列,这个是提高消费并发度的前提。
结构
每个消费队列对应一个逻辑文件,文件中对应每个消息的内容大小是固定的20个字节,包含消息的偏移量,大小以及tag哈希值。
文件目录
数据保存在目录${rootpath}/consumequeue下面,rootpath 通过配置项storePathRootDir指定,默认的是${user.home}/store。
${rootpath}/consumequeue
└── 0%default // topic
├── 0 // queue 0
│ └── 00000000000000000000
├── 1 // queue 1
│ └── 00000000000000000000
├── 2 // queue 2
│ └── 00000000000000000000
└── 3 // queue 3
└── 00000000000000000000
队列元素
|<----- 8 byte ----->|<- 4 byte ->|<------ 8 byte ------>|
+--------------------+------------+----------------------+
| commitlog offset | size | message tag hash code|
+--------------------+------------+----------------------+
执行
通过线程ReputMessageService的分派消息的逻辑执行。
写盘
系统每隔1000ms(可配置)进行一次消费队列的写盘操作。
核心代码
org.apache.rocketmq.store.DefaultMessageStore.FlushConsumeQueueService
清理消息
系统每隔10s(可以配置)执行尝试删除过期的消息。
清理条件
- 清理时间到达,默认是凌晨4点。
- 消息所在的磁盘使用率或者其他数据所在磁盘使用率操作告警阀值和强制删除阀值。
- 保存消息的目录通过配置项
storePathCommitLog指定,默认是$HOME/store/commitlog。 - 保存其他数据的目录通过配置项
storePathRootDir指定,默认是$HOME/store。 - 告警的磁盘使用率阀值通过系统变量
rocketmq.broker.diskSpaceWarningLevelRatio指定,默认是 0.9。 - 强制删除的磁盘使用率阀值通过系统变量
rocketmq.broker.diskSpaceCleanForciblyRatio指定,默认是 0.75。
- 保存消息的目录通过配置项
- 手动触发清理,这里提供了一个接口暴露给外面调用,调用以后会在连续执行20次删除。
清理逻辑
-
正常清理过期的消息,过期时间可以通过配置项
fileReservedTime指定,默认是72小时。 -
清理上次没有清理成功的消息,这是因为消息被清理时,其他地方正在使用。每隔一段时间执行一次,同时如果距离上次被清理时间超过了一段时间会被强制清理。
- 通过配置项
redeleteHangedFileInterval指定执行周期,默认120s。 - 通过配置项
destroyMapedFileIntervalForcibly指定强制清理的时间,默认120s。
- 通过配置项
核心代码
org.apache.rocketmq.store.DefaultMessageStore.CleanCommitLogService
清理消费队列以及索引
随着消息的清理,包含已经清理掉消息的消费队列以及索引就变得没有用处了,所以系统每隔100ms(可以配置)执行清理消费队列和索引。
清理逻辑
获取当前消息的最小偏移量,这个偏移量随着消息的清理会不停的变化。
- 消费队列:如果队列的最大消息偏移量都比当前最小的消息偏移量小,那么就可以清理本队列。
- 消息索引:如果索引中最大的消息偏移量都比当前最小的消息偏移量小,那么就可以清理本索引。
核心代码
org.apache.rocketmq.store.DefaultMessageStore.CleanConsumeQueueService
消息索引
消息索引是方便用户查询消息的一个结构。系统可以通过配置项messageIndexEnable开关消息索引,默认是打开的。索引允许重复构建,通过配置项duplicationEnable指定。系统启动的时候,如果允许重复索引会重头构建,不然就从当前文件大小开始。
索引内容
索引的key包含消息的两个属性:
KEYS,支持多个值,每个值之间通过空格分割。UNIQ_KEY。
索引的内容是消息的偏移量和时间(秒的精度)。
结构
目录结构
数据保存在目录${rootpath}/index下面,rootpath 通过配置项storePathRootDir指定,默认的是${user.home}/store。
index/
└── 20171225143756745
文件内容
每个文件内容分成3部分,header, slot table和index linked list。组织如下:
|<-- 40 byte -->|<--- 500w --->|<--- 2000w --->|
+---------------+------------------+-------------------+
| header | slot table | index linked list |
+---------------+------------------+-------------------+
header
+---------------------+--0
| beginTimestampIndex | ----> 第一条消息的保存时间
+---------------------+--8
| endTimestampIndex | ----> 最后一条消息的保存时间
+---------------------+--16
| beginPhyoffsetIndex | ----> 第一条消息的在commitlog中的偏移量
+---------------------+--24
| endPhyoffsetIndex | ----> 最后一条消息的在commitlog中的偏移量
+---------------------+--32
| hashSlotcountIndex | ----> 哈希槽数量,保存添加到本槽列表的最新索引位置
+---------------------+--36
| indexCountIndex | ----> 索引数量,具体索引数据
+---------------------+--40
slot table 和 index linked list
slot table总共有500w个位置,每个位置保存的是在这个slot上的索引列表中最新的那个索引。
index linked list保存每个消息的索引数据
- +-----+ <==== [slot table]
^ | 10 |
| +-----+
| | 200 |
| +-----+ +-----------+-------------+ +-----------+-------------+<=[index linked list]
| | 18 | --> | index data| next index |=>| index data| next index |
500w +-----+ +-----------+-------------+ +-----------+-------------+
| | ... | / \
| +-----+ / \------------------------------------\
| | 90 | |<--4 byte-->|<--- 8 byte --->|<--4 byte-->|<-----4 byte----->|
| +-----+ +------------+-------------------|------------+------------------+ <= [index]
v | 100 | | key hash | commit log offset | timestamp | next index offset|
- +-----+ +------------+-------------------|------------+------------------+
执行
通过线程ReputMessageService的分派消息的逻辑执行。
核心代码
org.apache.rocketmq.store.index
预分配MappedFile
写消息写到内存映射的文件,每次去新建一个文件同时会做内存映射操作,新建过程当中根据配置会执行比较耗时的预热操作。为了加快这个操作。系统通过一个线程预分配需要的MappedFile。具体逻辑就是在获取新的文件的时候发送两个请求,分别对应当前的需要的文件以及这个文件写满以后需要的下一个文件,然后等待直到预分配线程分配完当前需要的文件,或者超时。
核心代码
org.apache.rocketmq.store.AllocateMappedFileService
消息后续逻辑
当消息写入完成以后,系统有一个线程对消息可以做其他一些逻辑。比如:构建索引,消费队列,通知long pull的客户端请求。线程会维护一个消息索引,根据这个索引跟当前最大已经写入的消息的最大偏移量进行比较得到是否有消息需要处理。
当系统重启的时候,会根据duplicationEnable来决定是否从头开始处理消息还是只处理新来的消息。在duplicationEnable是true的情况下,还需要设置CommitLog.confirmOffset才能从头开始处理消息,因为默认情况下系统启动以后CommitLog.confirmOffset和ReputMessageService.reputFromOffset是相等的,详见代码ReputMessageService.doReput。
具体逻辑
- 分派消息:构建消费队列,消息索引。
- 同时long pull的客户端请求。
核心代码
org.apache.rocketmq.store.DefaultMessageStore.ReputMessageService
HA
RocketMQ的HA是最朴素的一主多从同步,主broker挂了从broker可以读数据,但是不能写,也不会自动主从切换。
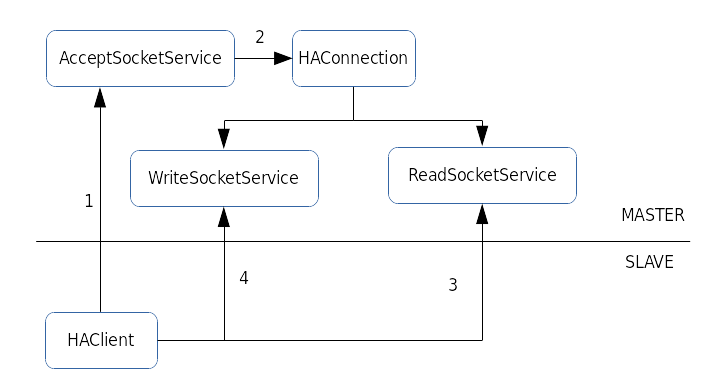
消息同步逻辑
- 启动的时候,MASTER会启动监听线程
AcceptSocketService,SLAVE会启动同步线程HAClient。 - 建立连接
HAConnection之后,MASTER会为连接建立两个线程WriteSocketService和ReadSocketService分别负责这条连接的写和读。 - SLAVE向MASTER报告,当前同步的位置,具体是到目前为止同步到的偏移量。
- MASTER根据SLAVE报告的偏移量,发送消息数据。
WriteSocketService线程
主结点向从结点推送消息线程。线程会记录当前同步的位置确保同步的数据不会重复。当线程启动的时候会等待从结点上报同步进度,如果上报的结果是0,从当前新消息文件中的第一个消息偏移量开始同步(不理解* V *)。消息写完主结点之后,会通知本线程进行写消息。另外,写完消息以后会主动向从结点发送已经同步的位置,像是一个保活机制。
ReadSocketService线程
接收从结点的同步进度。它的任务就是接收从结点同步进度,然后通知等待从结点写完的消息。
HAClient线程
从结点和主结点同步线程。主要工作
- 和主结点建立同步连接。
- 周期性的向主结点发送同步进度。
- 接收主结点推送过来的数据,并把数据写入磁盘。
- 检查是否有数据同步过来,有的话也会向主结点发送同步进度。
写buffer的影响
当开启写buffer的时候,主从同步的逻辑中使用到的当前消息的最大索引计算逻辑是不一样的。在这种情况下,系统会有一个线程CommitRealTimeService负责把写buffer中的数据写入文件。只有写入以后数据,才会被同步到从broker。也就是说主从同步的实时性还会受到这个线程的影响。
主从同步发送消息过程
当我们使用主从同步模式的时候,消息要等到主、从都写完才能返回。在这个过程中,除了主从同步逻辑以外还有消息等待从结点写完成的逻辑。这个逻辑是通过GroupTransferService完成的。大致流程如下:消息写完主结点后向GroupTransferService发送等待从结点写完请求,GroupTransferService只做一件事情,就是不断对比当前从结点同步进度与当前接收到的消息物理偏移量,如果从结点的同步进度大,说明消息已经写入从结点,随即通知消息已经写完。另外,从结点的同步进度是通过ReadSocketService接收到从结点主动发过来的;当消息写完主结点之后会通知主结点往从结点写消息服务WriteSocketService。
核心代码
org.apache.rocketmq.store.ha.HAService
org.apache.rocketmq.store.ha.HAConnection
定时任务
实现了定时调度某个消息的功能。用户通过给消息设置DELAY属性值来实现。
系统包含了一个名字为SCHEDULE_TOPIC_XXXX的topic,当消息指定了DELALY属性时,消息就会被发送到topic SCHEDULE_TOPIC_XXXX 中,同时会保存原来的topic、消费队列、以及其他属性值。这些值都作为消息的属性来保存。
系统通过配置项messageDelayLevel预定义可以延迟多长时间,同时每个延迟的级别对应着的消费队列。
系统通过一个定时器,周期性从每个延迟级别对应的消费队列中拿取消息,并检查是否到期,如果到期就会把消息放入到原来的topic和队列中,同时会把先前用于保存原来消息的属性值删除,并设置投递时间。
核心代码
org.apache.rocketmq.store.schedule.ScheduleMessageService
统计
消息的统计。包含:
- 发送消息的总数
putMessageTimesTotal - 发送消息时,不同响应时间级别的消息数量
putMessageDistributeTime - 发送消息请求的最长响应时间
putMessageEntireTimeMax - 发送消息的总大小
putMessageSizeTotal、平均大小putMessageAverageSize - 发消息的TPS
putTps - 拉取消息请求的最长响应时间
getMessageEntireTimeMax - 拉取消息请求命中TPS
getFoundTps、没有命中TPSgetMissTps以及总的请求TPSgetTotalTps - 拉取消息的TPS,拉取消息请求,并返回消息的TPS
getTransferedTps
核心代码
org.apache.rocketmq.store.StoreStatsService
写buffer
如果开启了这个功能,系统启动时会向系统申请多块写buffer。每块buffer都会被锁在内存中。这个buffer只会被commitlog使用,写消息的时候写到这些buffer。
核心代码
org.apache.rocketmq.store.TransientStorePool
内存映射的文件管理
rocketmq中的索引、消费队列、消息这些数据都通过内存映射进行读写。
映射文件
- 逻辑文件:数据按照顺序写入,由类
org.apache.rocketmq.store.MappedFileQueue表示 - 物理文件:具体写数据的文件,由类
org.apache.rocketmq.store.MappedFile表示
它们之间的关系:
|<- MappedFileQueue ->|
+-------------------+--------------------+-------------+-------------------+------------------+
|000000000000000000 | 000000000000000100 | ... |000000000000010000 |000000000000020000|
+-------------------+--------------------+-------------+-------------------+------------------+
|<- MappedFile-0 ->|<- MappedFile-1 ->| ... |<- MappedFile-n-1->|<- MappedFile-n ->|
+-------------------+--------------------+-------------+-------------------+------------------+
一个 MappedFileQueue 由多个 MappedFile 组成,每个 MappedFile 文件大小相等,文件名是32个字符,并且表示当前文件中第一个记录在 MappedFileQueue所代表的逻辑文件中的偏移量。
引用计数
MappedFile在一个多线程环境里面,在使用的时候有可能已经被执行了删除操作,通过引用计数的方式进行安全管理MappedFile的生命周期。
优化
预热
- 新建
MappedFile时通过先把文件映射的内存都写一遍,内核为文件分配物理页。 - 使用
mlock锁住文件映射的物理内存,确保这部分内存不被交换出去。 - 使用
madvise通知内核这部分数据将来会读到。
写buffer
建立一个buffer池,这些buffer是堆外内存。buffer所占用的内存是不会被交换出去的,同时也会通知内核这部分数据将来会读到。MappedFile新建的时候可以通过这个池子获得buffer作为写的buffer。
核心代码
org.apache.rocketmq.store.MappedFileQueue
org.apache.rocketmq.store.MappedFile
备注
代码版本
4.1.0
参考文档
RocketMQ design