RocketMQ支持主结点的数据同步到从结点。同步的数据依赖于当前从结点的状态。从结点连接到主结点的时候会上报自己的当前commitlog的最大偏移量。主结点收到以后会根据这个值计算出传输的起始位置,如果上报的commitlog的最大偏移量:
所以,这里我们可以知道如果从结点已经就有数据情况,如果数据不是从主结点同步过来的,那么同步之后就会有问题了。比如说:从结点已经有10000条数据,同时某个topic,暂时就叫OLD_TOPIC的*消费队列0*长度1000。这个时候,主结点就会从第10000条数据开始同步,可能会发送几种情况:
所以,从结点的初始状态需要从0开始或者本来就是和主同步过的状态。因此,在删除topic的时候从结点要保证删除干净,不然从结点就会脏数据,影响消费。
为什么这样同步不会有问题呢?
那是因为同步的数据里面包含了具体消费队列ID,队列中的偏移量以及消息的偏移量,所以同步的时候能够写到同一个位置。
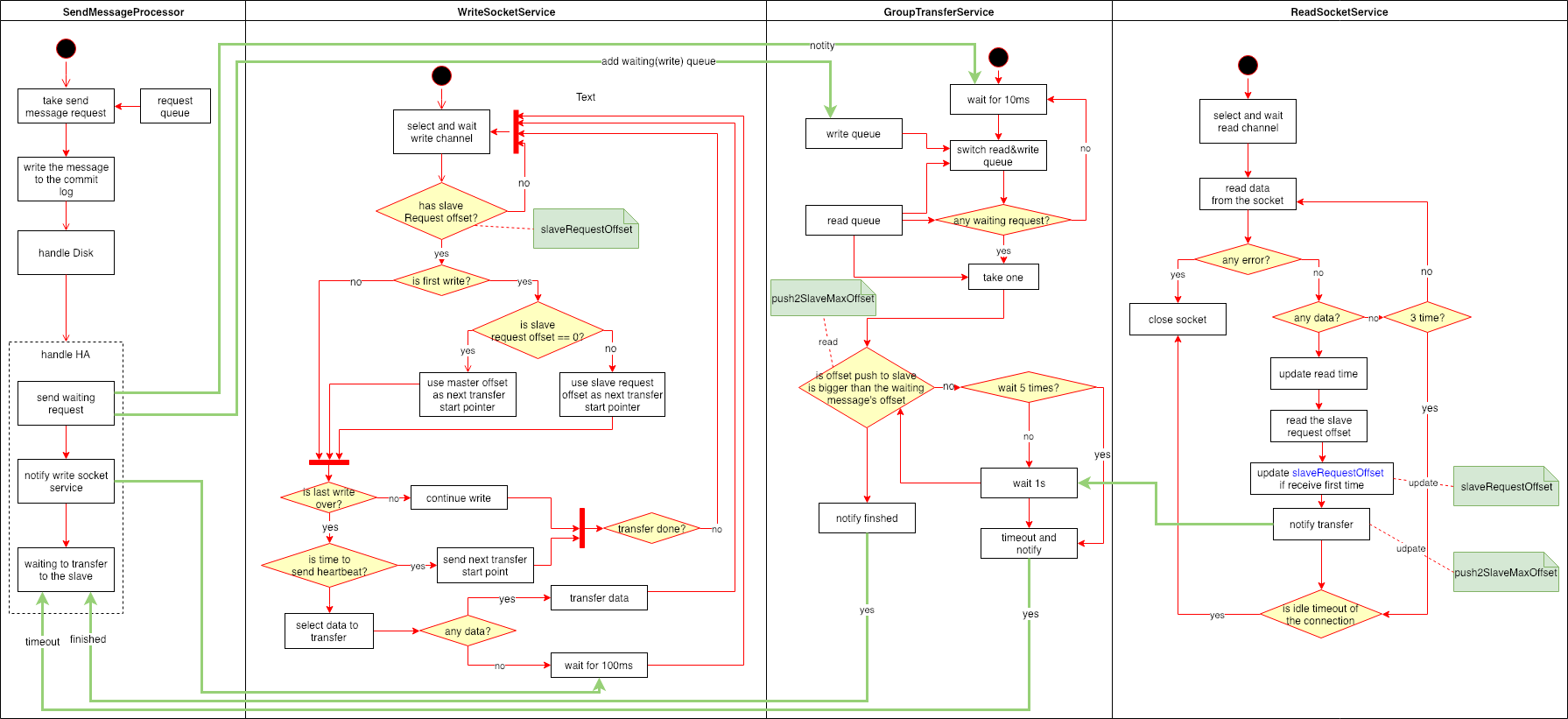
发送一条消息的时候,在开启SYNC_MASTER情况下,需要四个线程合作才能完成消息的发送。
slaveRequestOffset),不断的向从结点传输数据。同时会维护和从结点的一个心跳,如果一段时间没有通不过数据,就会发送一个消息头,包含当前同步的起始位置。push2SlaveMaxOffset)和SendMessageProcessor发送过来的请求中包含的偏移量,如果大于或者等于就会通知SendMessageProcessor。push2SlaveMaxOffset和slaveRequestOffset并通知GroupTransferService。从而,它也会影响WriteSocketService的行为。同时,它还维护着和从结点连接的过期工作,如果超过指定时间没有收到消息就会断开连接,同时会停止WriteSocketService。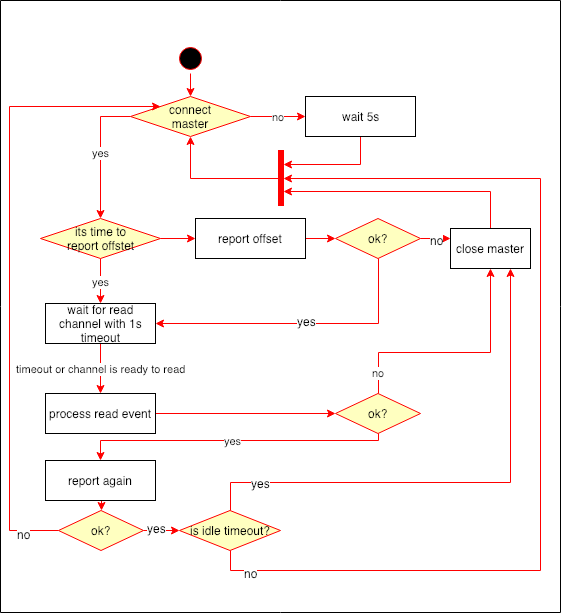
从结点的同步逻辑相对简单主要做几件事情:
lastWriteTimestamp中,刚刚连接上主结点和从主结点读到数据都会更新该变量。